
장난감 연구소
[DB/JPA] Index와 EntityGraph 적용 과정 정리 본문
MariaDB와 Hibernate(JPA)를 활용하여 프로젝트를 진행하며 데이터베이스 쿼리 성능 최적화와 관련된 작업을 정리하였습니다. 이 내용은 개인 기록용으로 작성되었습니다.
인덱스(Index)

23년 여름, 동아리 홈페이지를 개발하면서 서버 개발을 담당했습니다. 데이터베이스로는 관계형 DB인 MariaDB를 사용하였습니다.
홈페이지에는 커뮤니티(게시판) 기능이 존재하며, 위 사진과 같이 기본적인 게시판 형태를 가지고 있습니다. 기본적인 제목, 본문 외에도 첨부파일 업로드, 댓글, 좋아요/싫어요 기능을 구현하였습니다.
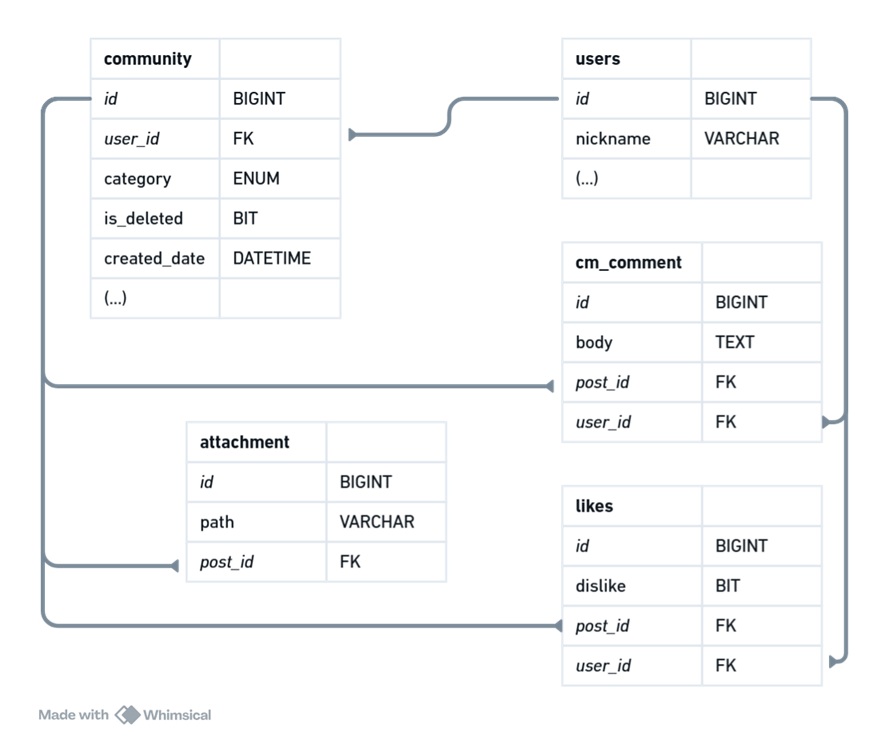
커뮤니티 기능과 관련된 테이블 구조는 위와 같습니다. 다른 필드가 여러 개 존재하지만, 간단히 핵심적인 부분만 표시했습니다.
인덱스 설계 및 생성
얼마 지나지 않은 코드지만, 다시 보면 부족한 점이 많다는 것을 느낍니다.
당시에는 모르는 것도 지금보다 많았고, 빠르게 결과물을 만들고자 하였기에 완성도가 떨어지는 부분이 있었습니다. 이후 Spring 강의를 통해 새로운 기능을 배우고, 졸업 작품을 진행하면서 개선해야 할 부분이 하나둘 눈에 띄기 시작했습니다.
그중에서도 가장 큰 문제는 DBMS 사용 시 인덱스를 적용하지 않았던 점입니다.
비록 데이터량이 많지 않아 성능에 큰 영향을 미치지는 않지만, 앞으로 데이터가 늘어났을 때 성능 개선과 DB에서 인덱스는 기본이란 점을 생각하면, 반드시 개선해야 할 부분이긴 했습니다.
게시판에서 가장 많이 발생하는 요청은 게시글 목록을 조회하는 요청입니다. 해당 요청에서 JPA가 사용하는 쿼리는 아래와 같습니다.
SELECT *
FROM community c INNER JOIN users u ON u.id = c.user_id
WHERE NOT(c.is_deleted)
ORDER BY c.created_date DESC LIMIT ?, ?;
위 쿼리에선
- c.is_deleted = 0 필터링
- u.id = c.user_id 조건으로 users 테이블과 community 테이블 조인
- c1_0.created_date 내림차순 정렬
- LIMIT ?, ? 페이징
을 합니다.
따라서 community (is_deleted, created_date)로 인덱스를 만들어 is_deleted로 필터링한 후, created_date를 기준으로 빠르게 정렬할 수 있게 하였습니다.
인덱스 생성
MariaDB(MySQL)에서 인덱스를 생성하려면 아래 쿼리를 사용합니다.
CREATE INDEX <index_name> ON <table_name> (column_name1, column_name2, ...);인덱스 삭제
인덱스 삭제는 아래 쿼리를 사용합니다.
DROP INDEX <index_name> ON <table_name>;인덱스 조회
테이블의 인덱스 목록을 조회하려면 아래 쿼리를 사용합니다.
SHOW INDEX FROM <table_name>;
속도 비교
비교 방법
인덱스 생성 전후의 소요시간을 비교하기 위해서는 쿼리 프로파일링 기능을 이용할 수 있습니다.
# 프로파일링 활성화 (0은 비활성화)
SET profiling = 1;
# 실행한 쿼리 목록 및 소요시간 표시
SHOW PROFILES;
# 특정 쿼리에 대해 상세 소요시간 표시
SHOW PROFILE FOR QUERY <query_id>;
# 쿼리 결과 캐시 초기화
RESET QUERY CACHE;
# 쿼리 실행계획 확인 (인덱스 사용 여부 확인)
EXPLAIN SELECT * FROM <table_name> ...<condition>... /*(확인할 쿼리)*/;
결과
앞서 얘기한 바와 같이 community (is_deleted, created_date) 인덱스를 만들고, 소요시간을 비교하였습니다. 비교를 위해 가짜 데이터를 늘려 community 테이블의 데이터를 200,000행(약 69.6MB)으로 만들고 소요시간을 비교하였습니다.
- 인덱싱 이전
MariaDB [tuxweb2]> EXPLAIN SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10;
+------+-------------+-------+------+---------------+---------+---------+--------------+-------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+---------+---------+--------------+-------+---------------------------------+
| 1 | SIMPLE | u | ALL | PRIMARY | NULL | NULL | NULL | 6 | Using temporary; Using filesort |
| 1 | SIMPLE | c | ref | user_id | user_id | 9 | tuxweb2.u.id | 19954 | Using where |
+------+-------------+-------+------+---------------+---------+---------+--------------+-------+---------------------------------+
2 rows in set (0.001 sec)
MariaDB [tuxweb2]> SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10;
<데이터 출력 생략>
MariaDB [tuxweb2]> SHOW PROFILES;
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 0.00019530 | RESET QUERY CACHE |
| 2 | 0.00107890 | EXPLAIN SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10 |
| 3 | 2.43703670 | SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10 |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.000 sec)- 인덱싱
MariaDB [tuxweb2]> CREATE INDEX community_list ON community(is_deleted, created_date DESC);
Query OK, 0 rows affected (0.040 sec)
Records: 0 Duplicates: 0 Warnings: 0- 인덱싱 이후
MariaDB [tuxweb2]> EXPLAIN SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10;
+------+-------------+-------+--------+------------------------+----------------+---------+-------------------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+--------+------------------------+----------------+---------+-------------------+-------+-------------+
| 1 | SIMPLE | c | range | user_id,community_list | community_list | 1 | NULL | 99772 | Using where |
| 1 | SIMPLE | u | eq_ref | PRIMARY | PRIMARY | 8 | tuxweb2.c.user_id | 1 | |
+------+-------------+-------+--------+------------------------+----------------+---------+-------------------+-------+-------------+
2 rows in set (0.004 sec)
MariaDB [tuxweb2]> SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10;
<데이터 출력 생략>
MariaDB [tuxweb2]> SHOW PROFILES;
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | 0.00023720 | RESET QUERY CACHE |
| 2 | 0.00385390 | EXPLAIN SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10 |
| 3 | 0.00749330 | SELECT * FROM community c INNER JOIN users u ON u.id = c.user_id WHERE c.is_deleted = 0 ORDER BY c.created_date DESC LIMIT 500, 10 |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.000 sec)인덱싱 이후 EXPLAIN 출력 결과 type이 range로 출력된 것에서 range scan으로 인덱스가 사용된 걸 확인할 수 있었습니다.
결과적으로 소요시간이 0.105초에서 0.089초로 약 15.24% 감소하였습니다. (이는 6,094행 테이블의 결과로 데이터의 수를 보강하여 다시 테스트하였습니다.)
결과적으로 200,000행의 테스트 데이터에 대한 조회 소요시간이 2.473초에서 0.007초로 약 99.67% 감소하였습니다.
올바른 인덱스의 중요성을 느낄 수 있었으며, SQL 튜닝에 대해 더 깊이 공부하려 생각하고 있습니다.
N + 1 문제
동아리 홈페이지 개발 프로젝트를 돌아보던 중 알게 된 다른 문제는 N+1 문제입니다.
N+1 문제는 데이터베이스에서 한 번의 조회로 가져올 수 있는 데이터를 여러 번의 개별 쿼리로 가져오는 상황을 말합니다. 예를 들어, 부모 엔티티를 1번 SELECT로 가져오고, 관련된 자식 엔티티를 각각 개별 쿼리로 가져오는 구조입니다.
프로젝트에서는 ORM 툴로 Hibernate(JPA)를 사용하여 게시글 목록을 조회합니다. 이때 community 테이블에서 SELECT를 한번 날리고, 글쓴이(users)와 첨부파일(attachment), 댓글(cm_comment), 좋아요(likes)를 각각 조회하고 있었습니다.
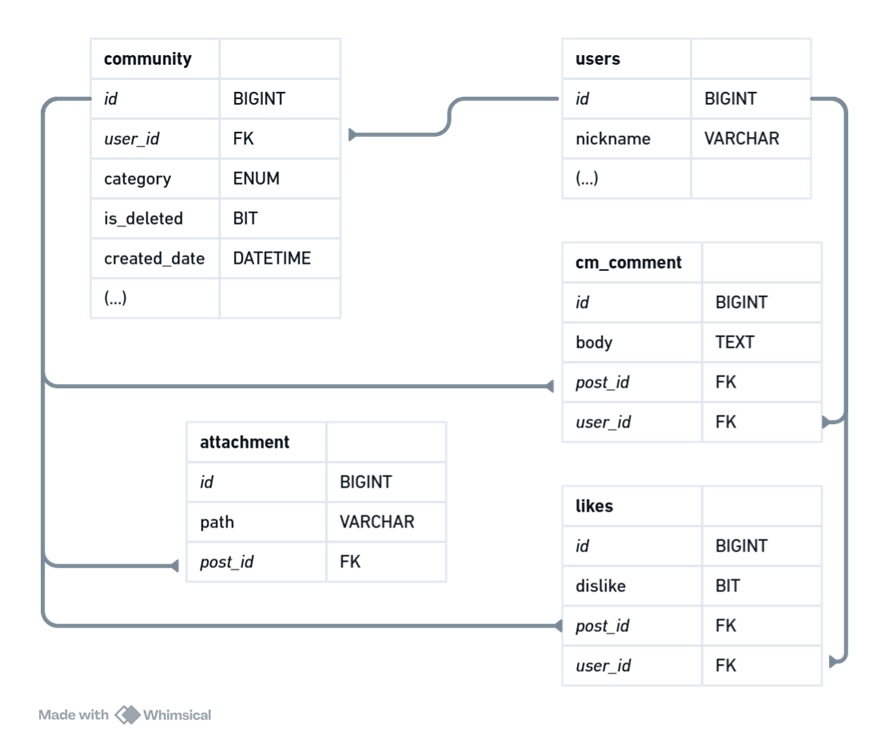
참고로 JPA에서 날리는 쿼리를 출력하려면 application.properties 파일에서 아래와 같이 설정하면 됩니다.
spring.jpa.properties.hibernate.show_sql=false
spring.jpa.properties.hibernate.format_sql=false
@EntityGraph
이를 위해 Community 엔티티 클래스에 @EntityGraph를 적용하여 회원 엔티티를 JOIN을 통해 한번에 조회하도록 개선하였습니다.
@Entity
@Data
@NamedEntityGraph(name = "Community.fetchUser", attributeNodes = @NamedAttributeNode("user"))
public class Community {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
(...)
}@Repository
@Transactional(readOnly = true)
public interface CommunityRepository extends JpaRepository<Community, Long> {
@EntityGraph("Community.fetchUser")
Page<Community> findByIsDeletedFalseOrderByCreatedDateDesc(Pageable pageable);
(...)
}@EntityGraph 어노테이션은 특정 쿼리 실행시 Eager 로딩을 명시적으로 지정하여 연관 엔티티를 한번에 로드하도록 합니다. @NamedEntityGraph는 @EntityGraph를 미리 정의해두고 예시의 Repository 코드처럼 단순히 이름만 적어 사용할 수 있게 해줍니다.
이에 대한 내용은 아래 영상을 참고하면 됩니다.
개선 방향
현재 게시글 목록 조회 중 community 테이블과 users 테이블은 JOIN을 통해 한번에 조회하도록 처리했지만, 첨부파일(attachment), 댓글(cm_comment), 좋아요(likes) 테이블은 여전히 N+1 문제가 남아 있습니다.
이를 해결하기 위해 다른 엔티티에도 EntityGraph를 사용해 JOIN으로 함께 조회하도록 시도하였으나, 의도와 다르게 모든 데이터를 메모리에 적재하여 정렬하게 되어 성능 문제가 나타날 가능성이 있었습니다. 이는 community 엔티티가 users 엔티티를 하나만 가지는 반면, 나머지 엔티티를 N개 가지는 구조때문이라 판단됩니다.
처음 게시판 기능을 개발할 때 첨부파일, 댓글, 좋아요와 같은 부가적인 기능을 충분히 고려하지 않은 점이 위와 같은 문제를 심화시켰습니다. 특히 게시글 목록 조회에서 댓글 수와 좋아요 수를 보여주는 기능이 필요해지면서, 각 게시글마다 댓글 테이블과 좋아요 테이블을 추가로 조회하는 작업이 발생하였습니다.

앞으로 개발할 때는 위 다이어그램처럼 게시글 목록 조회에서 굳이 댓글과 좋아요 테이블을 조회하지 않기 위해, 댓글 수와 좋아요 수를 community 테이블에 미리 저장해두는 방식으로 개발해야겠다고 생각합니다.
'개발 > DB' 카테고리의 다른 글
| [DB] 가까운 순 조회시 H3 인덱스 적용해보기 (0) | 2025.12.27 |
|---|---|
| [MySQL] 공간 인덱스는 충분히 빠를까? (0) | 2025.12.07 |
| [캐시] 캐시 문제 해결 가이드 (0) | 2025.08.26 |
| [MySQL] 가까운 순 조회시 공간 인덱스 사용 (0) | 2025.07.17 |


